I am using macOS 12.5.1, VirtualBox 6.1 and latest extensions, ChipWhisperer VM 5.6.1.
I have tried multiple Jupyter glitch courses+solutions without success. Same story every time, the glitch resets the target always, independently of the ext_offset value.
As soon as I set a scope.glitch.repeat greater than 0, and even if I use an infinite scope.glitch.ext_offset, the target is reset instantly.
Is that a bug in the new release? Is it a hardware defect?
SOLN_Fault 2_1B - Introduction to Voltage Glitching with CWNano resets the target hundreds of times but there’s never a normal nor a success response from the target.
Not sure if this is a new bug or expected behaviour - the Nano glitch is very limited compared to Lite/Pro/Husky due to being done just by a microcontroller interrupt and those doc numbers are just estimates based on those limitations.
It seems that the 2500 iterations loop lasts approximately 6ms.
I have managed to grow the ext_offset up to 805500 and I start to get back the initial bytes of the normal count response (see below), and successively the reset, making a weird ‘rCrRESET’ message. Higher than this and the experiment becomes unresponsive, unsure why, probably a timeout?
So, the ext_offset is actually taken into account. The biggest problem seems to be the glitch length that is too large, resetting the target every time and never affecting the loop behaviour.
Thanks for tests - I’m trying to find notes on why it’s done the way it is. From memory in previous experiments - running out of SRAM (which would make it easier to generate the code) was too slow. The SAM4S datasheet/manual has a note that running from SRAM isn’t as optimal, since you can’t have simultaneous data & code access:
The original idea/code would generate your delay function in SRAM, and run that function. But if you need to do that in flash it means an erase/write cycle which has a limited lifespan.
We played around a bit trying to get around this (don’t have data access) but from memory it was always slower, so ended up with the implementation you see now.
On current implementation - you could remove that loop, tbh I’m wondering if it wasn’t meant to be present on the lowest setting (maybe we assumed it would get optimized away, but had an off-by-1 error in our assumption?). That seems like a bug as you’d want the smallest possible value.
But I think it makes sense to remove that loop in the lowest, and maybe adjust this so the first few “steps” have more precision.
What might be easier to get successful glitches will actually be making the STM32F0 “more unstable” - this can be done by increasing the core frequency, and being sure to disable the flash access wait states.
Looking at the generated assembly, it should be possible to save a cycle or two via some inline assembly, as the loop setup is done after the gpio is set. I think this CPU also has conditional stores, so we might be able to get close to the shortest case here (“cmp loopvar”, “isb”, “gpio_high”, “conditional gpio_low”, “loop”, assuming none of the instructions between cmp and the conditional update the status flags).
Hi Colin, thanks a lot for the explanation on the SRAM issue that I was totally unaware of.
On current implementation - you could remove that loop, tbh I’m wondering if it wasn’t meant to be present on the lowest setting (maybe we assumed it would get optimized away, but had an off-by-1 error in our assumption?). That seems like a bug as you’d want the smallest possible value.
There isn’t an off-by-one because the width is repeat/3. So when you pick 1 as repeat, you end up with zero.
The main issue is the generated assembly code that loads from memory at the initialisation of the loop. The 2 loads from memory may take quite a long time. There’s also the fact that there’s an actual comparison+branch done after an ISB even for repeat=1.
Your idea of hardcoding hand-optimized versions for the smallest repeat values could be great, my biggest question about that is how would you make the transition from hardcoded to the loop? There will probably be some behaviour gap depending on the length of the glitch.
But that may not be of great importance, considering I sometimes have 20ms or 40ms between values for no explanation; Pipeline related?
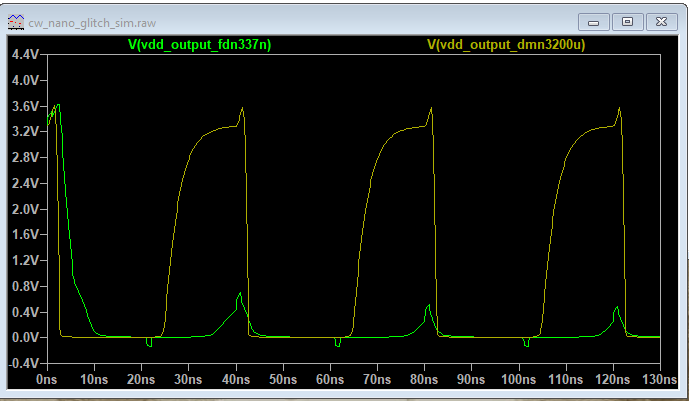
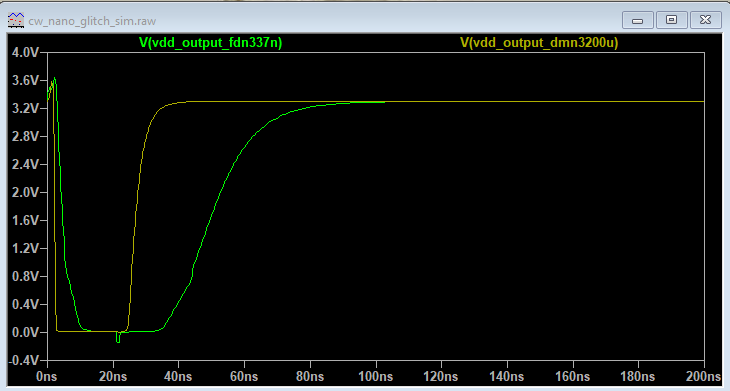
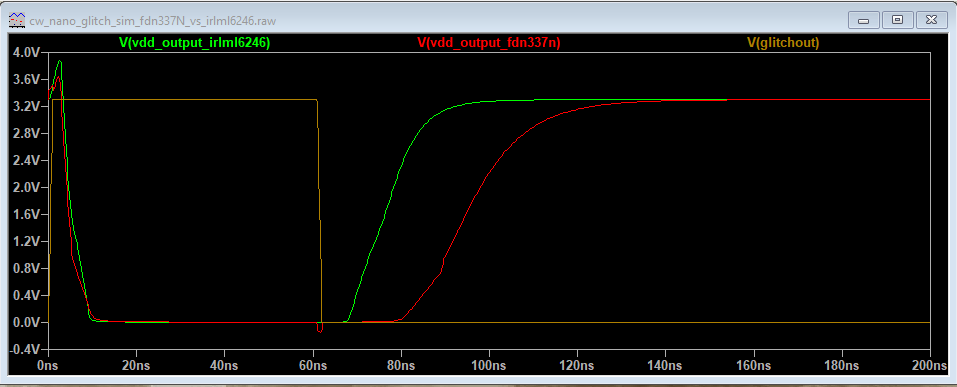
For fun I did a quick simulation ( GitHub - rlangoy/cw_nano_glitch_sim: ChipWhisperer Nano glitch simulation using LT-SPICE) comparing the glitch output using DMN3200U (the original glitching transistor) vs the FDV337N (the new one)
(I am not sure about the quality of the DMN3200U model…)
The result from the FDV337N simulation matches you mesaurement