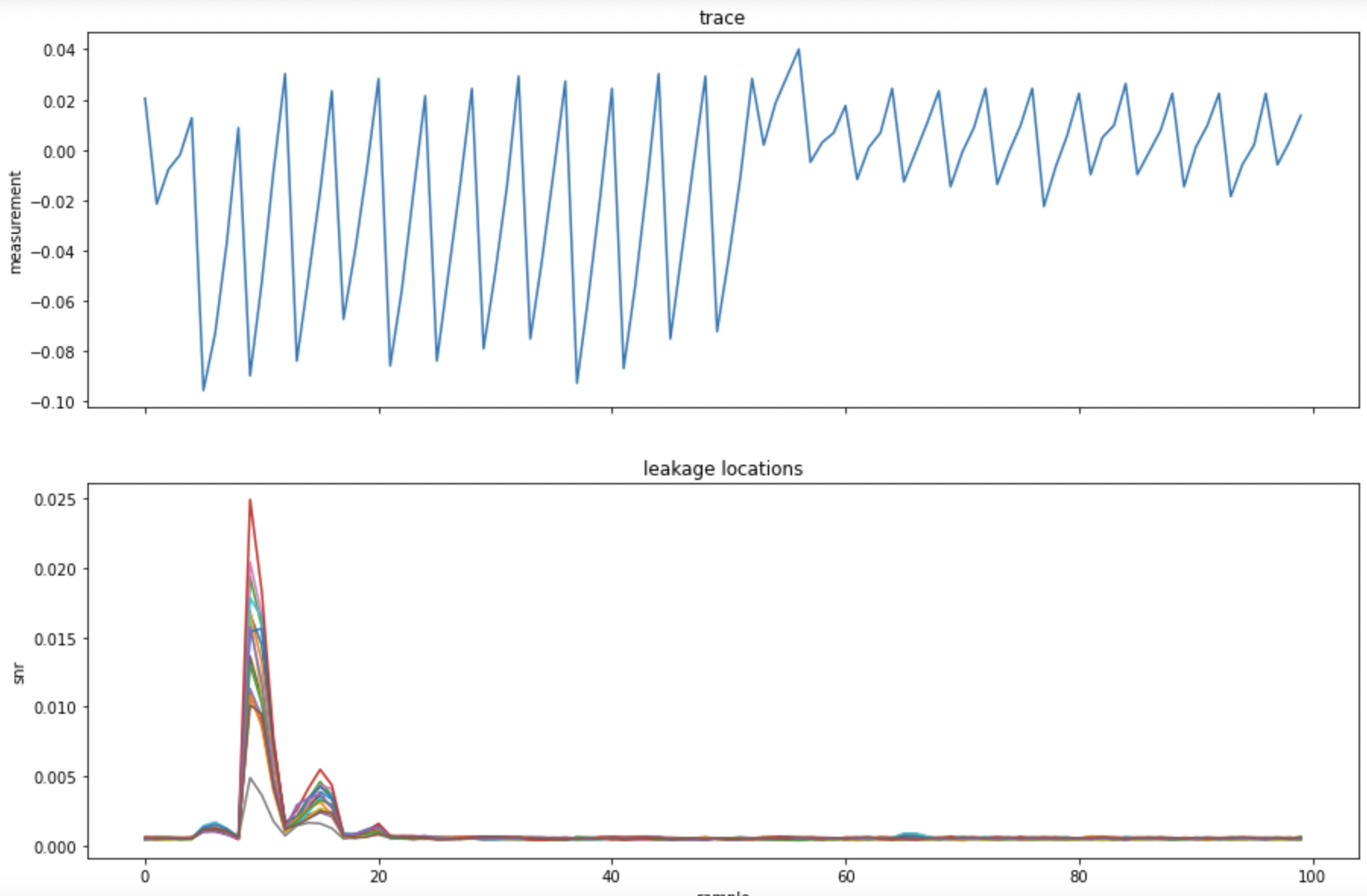
Is there a way to adjust how fast the CW305 FPGA runs AES, and am I correct in thinking that leakage models would perform better at slower speeds? I’m having trouble capturing traces fast enough to be able to differentiate which part of a trace relates to the processing of the s-box operation for individual bytes. For example, in this image I’ve calculated and plotted the leakage for the first round s-box operation. There seems to be a correlation early on in the trace, but the CW-Lite scope is too slow relative to the FPGA to be able to capture the individual substitutions it seems, as all leakage spikes are overlapping. I’d appreciate your help!
The reason you’re not seeing success attacking the SBox of the AES implementation on the CW305 is because that the outputs of the SBox aren’t really being stored like they are with a software implementation of AES. It’s not really a matter of clock speed, it’s how the AES is actually working.
Thank you for your response. I have ran this Notebook before and was able to get successful results using the built-in CPA attack and the leakage model you’re referring to, but I’m having trouble understanding how it actually works. That’s why I was trying something else. Could you please explain how the last round state diff model helps reveal the key? Using deep learning with the first round s-box model, I’m able to label traces zoomed in to a specific byte’s substitution with s-box[plaintext byte ^ key byte] and then train a model to predict the s-box values for future traces and work backwards to the key having known the plaintext. What would be the equivalent of that for the last round state diff model? My understanding is that it determines the Hamming distance between bytes of the last two round’s outputs, but I don’t see how that actually makes it possible to determine the key. Sorry for the confusion about this.
You only get significant power leakage when the AES state is stored in a register, which is done between rounds for this implementation, not after the SBox like with a microcontroller implementation. This is a problem for the first round because there’s a mixcolumns operation in there, which means we can no longer attack a single byte at a time, we have to instead attack four (there’s a way around this, but it makes the attack much more complicated: https://github.com/newaetech/chipwhisperer-jupyter/blob/master/experiments/MixColumn%20Attack.ipynb if you’re interested).
The last round doesn’t have a mixcolumns, which makes it much easier to attack. We use a state diff here because the register isn’t cleared between writes like it typically is for a microcontroller.
The attack itself is working the same, we’re just comparing our power traces to a different part of the AES state, this time working backwards from the ciphertext.
Okay, that makes sense, but I’m still confused on how you can work backwards to the key from the ciphertext. Wouldn’t I need to know the input coming into the last round in order to figure out what the last round key was? With the first round s-box model I had two knowns and 1 unknown (as I knew the input plaintext to the first round and I assumed that my model could predict the s-box output value for me, and having known those two things I could run quick for loop from 0-255 to determine the corresponding key byte). For the last round though, if I only know the ciphertext, both the input to the last round (the equivalent of the plaintext for the first round) and the last round key are unknown. What values are you assuming I could use to work backwards to the last round key?
You can work backward from the ciphertext. Your power trace will be proportional to the difference between the last two rounds, which only depends on the key (which you’re trying to find) and the ciphertext (which you know). This is the same situation as going forward from the plaintext, where the sbox output that your power trace is proportional to, only depends on the key (which you’re trying to find) and the plaintext (which you know).
Sorry Alex, I don’t understand how the Hamming distance, or the difference, between the last two rounds is useful to me like the s-box value was. If for example a model can predict for me that the difference between the first byte of the input to the last round and the first byte of the ciphertext is 3, what sort of function or equation would I use to figure out the last round key from that? Aren’t there a number of values that the first byte of the input to the last round could have been to result in a difference of 3 bits between it and the ciphertext byte?
Yes, but you can say the same thing for the SBox: for example, the sbox can output 23, 32, 94, 92, 83, E0, 0E, and so on, which all have a hamming weight of 3. There’s actually very little difference between the leakage model for the last round state diff and the SBox that we use for software AES. The equation for the leakage for the last round state diff is:
def leakage(self, pt, ct, key, bnum):
# HD Leakage of AES State between 9th and 10th Round
# Used to break SASEBO-GII / SAKURA-G
st10 = ct[self.INVSHIFT_undo[bnum]]
st9 = inv_sbox(ct[bnum] ^ key[bnum])
return (st9 ^ st10)
They both only depend on a single byte of the key and our known values (plaintext/ciphertext).
I think you might be thinking of this in the wrong way - we’re going from the ciphertext backwards. We don’t care at all about what comes before the last two rounds, just like we don’t care about what comes after the sbox with the normal sbox leakage model.
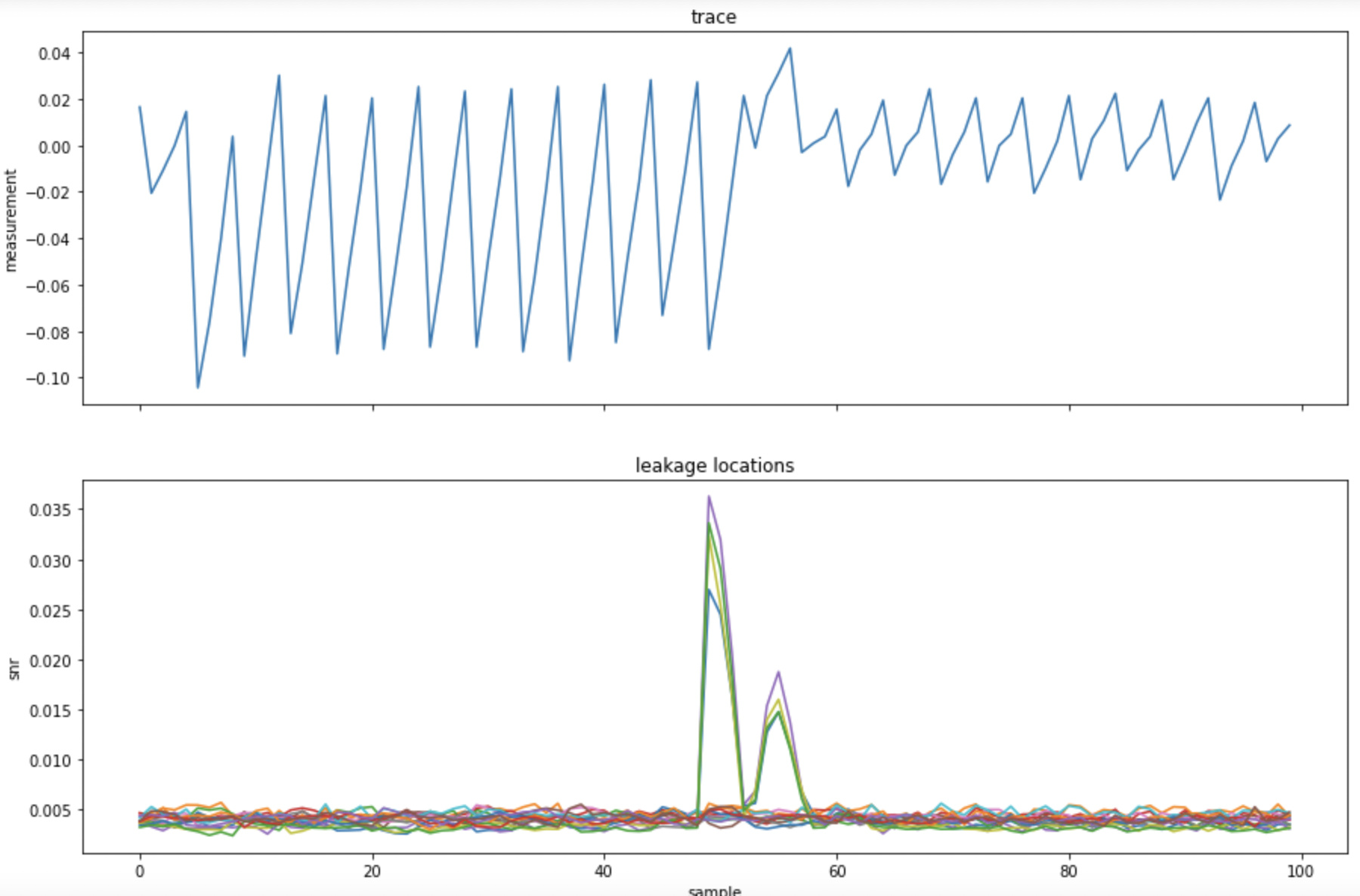
I think it’s becoming more clear to me now. I really appreciate all your help! I tried using that leakage model on my training dataset and ended up with an SNR plot like this:
The spikes correspond to bytes 0, 4, 8, and 12, and using several samples from the original traces centered on peak SNR index 49, I was able to recover those 4 key bytes with only roughly 10-20 traces using deep learning. However, I was not able to recover the rest of the bytes (even with a test dataset of 30,000 traces). Should I have seen an SNR spike for the other 12 bytes as well, or is there another level of complexity to this leakage model or AES implementation that I still need to account for to recover the others?
Did you use the exact leakage model that I linked? One difference between the usual SBox and the last round state diff is that there’s a shiftrows in that, meaning that bytes 0, 4, 8, and 12 line up between rounds 9 and 10, but this isn’t true for the rest of the bytes. Byte 1, for example, for the key and round 9 will correspond instead to byte 5 in the ciphertext.
I adapted it slightly to fit with my prior code, but I think it’s the same. I have the ciphertext and key stored in a dictionary called “trace” that I pass to the function along with the byte number of interest. Did I get the shift array correct?
That INVSHIFT does look correct. I’m not too sure then why bytes 0, 4, 8, and 12 are working but the rest aren’t. Perhaps experiment with the leakage model a bit (remove the invshift, do a shift on the st9 key/ct, etc)?
I figured out my issue. I was using the first round key instead of the last for my leakage
Having changed that I was able to recover the full key! I’m a little curious as to why I was able to get bytes 0, 4, 8, and 12 at all using the original key… but regardless I’m glad it worked with the change.
I am working on a serial hardware implementation of AES which stores the states of the round’s addkey, subbyte, shiftrow, and mixcol outputs. There is only one round instance that is used repetitively.
In the “PA_HW_CW305_1-Attacking_AES_on_an_FPGA” I tried the three models of “last_round_state_diff”, “sbox_output”, and “plaintext_key_xor”. The latter two models did not work (failed to recover the key). Is there something else that I need to modify in the attack setup to get it work with these two models?
You’ll likely need to use the state difference here (aka old XOR new), not just the state of the register. This is pretty common for HW/FPGA AES implementations. Last round state diff is probably the only reasonable one.