Hi everyone.
I use the CWLite-32 ARM (STM32F), and my goal is to perform a template attack on TINYAES128 to recover the full secret key (16 bytes). I do not know the key, as encryption using the secret key is done with a given .hex file which used it (that file always uses this key and is otherwise identical to the regular TINYAES128 implementation).
I have read material on template attacks from a few sources, including the deprecated ChipWhisperer wiki, and written my own code to perform the attack on all 16 bytes.
After completing the attack and recovering a best guess for the key, I tried encrypting bytearray([0]*16) first using the recovered key, and then using the secret key (I made sure to reprogram the target before each of these encryptions to use the correct implementation).
I noticed that the 2 ciphertexts obtained are different, so the recovered key is probably incorrect.
I started changing stuff in the code trying to figure out what the problem is with no luck.
Here’s a list of what I tried to do, and what I’ve noticed so far:
- Pick POIs once based off SAD and then based off SNR
- Use 1, 2, …, up to 10 POIs for each subkey/byte (instead of 5)
- Make sure attack traces are captured immediately after the profiling traces
- Use 5000 to 30000 profiling traces and 100 to 5000 attack traces
- In the profiling phase I have attempted both capturing 1 trace for each random key-plaintext pair, and capturing 10 traces for each pair and saving the mean trace (to reduce noise)
- Capturing 3000 to 5000 samples per trace (at different attempts)
After all of these, I still end up getting an incorrect key.
I have noticed a few things that might indicate the source of the problem, but I couldn’t make use of them:
The covariance matrices (created in the profiling phase) are filled with very low-scaled values, usually ranging from 1e-4 to 1e-8.
Example image, covariance matrix for first subkey/byte, hamming-weight 0:
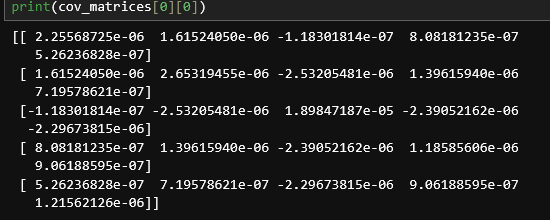
Using SciPy’s multivariate normal, the .logpdf() function works, but trying to use np.log(multivariate_normal.pdf()) throws a division by 0 error. I assume this is because the values are incredibly small, but I do not know if it’s usual. Maximum log-likelihood values are usually in the scale of (negative) millions.
Additionally, each time I capture new traces and run the exact same code, the recovered key changes, yet the best guess of each subkey/key-byte appears to be dominant after enough attack traces, even though acquiring new attack traces yields a different value.
One important note I’d add is that I even tried completely copy-pasting the code from the tutorial in the CW wiki into a loop of 16 iterations to recover each byte, and still got an incorrect key (and the covariance matrices are of the sane scale as previously), which makes me think the problem is not in the code.
Turning off my antivirus, using a different USB port and even a different computer also did not help.
At that point, I’m quite clueless on what could be the root of the problem, so any assistance will be greatly appreciated!