Hi, I am trying to understand how shuffling the order of the S-Box lookup affects the number of traces needed for a successful attack. I am consulting ‘Power Analysis Attacks: Revealing the Secrets of Smart Cards’ By Stefan Mangard et al.
Eq. 8.8 (on Page 210) states that : If the power consumption of l clock cycles is independently distributed and if the variances of the power consumption in all cycles are equal, the sum of the power consumption leads to the following correlation coefficient for the correct key hypothesis.
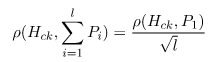
My question is: which operations are being ‘integrated’ for this to apply? So for the 16 S-Box lookups, if each lookup (i.e., L0, L1 …L15) can be in any of the 16 ‘positions’ per trace, does the attacker need to know where each of the lookups happens to do this integration?
Without this information, I’m not getting how integration can be done without a brute-force approach of checking every possible combination of positions.
Any help/clarity would be much appreciated!